

Keeping supporters up to date using AWS Events and Web Push (part 1)
How I built a solution to keep supporters of a sports club up to date using an event-driven architecture in AWS and Web Push


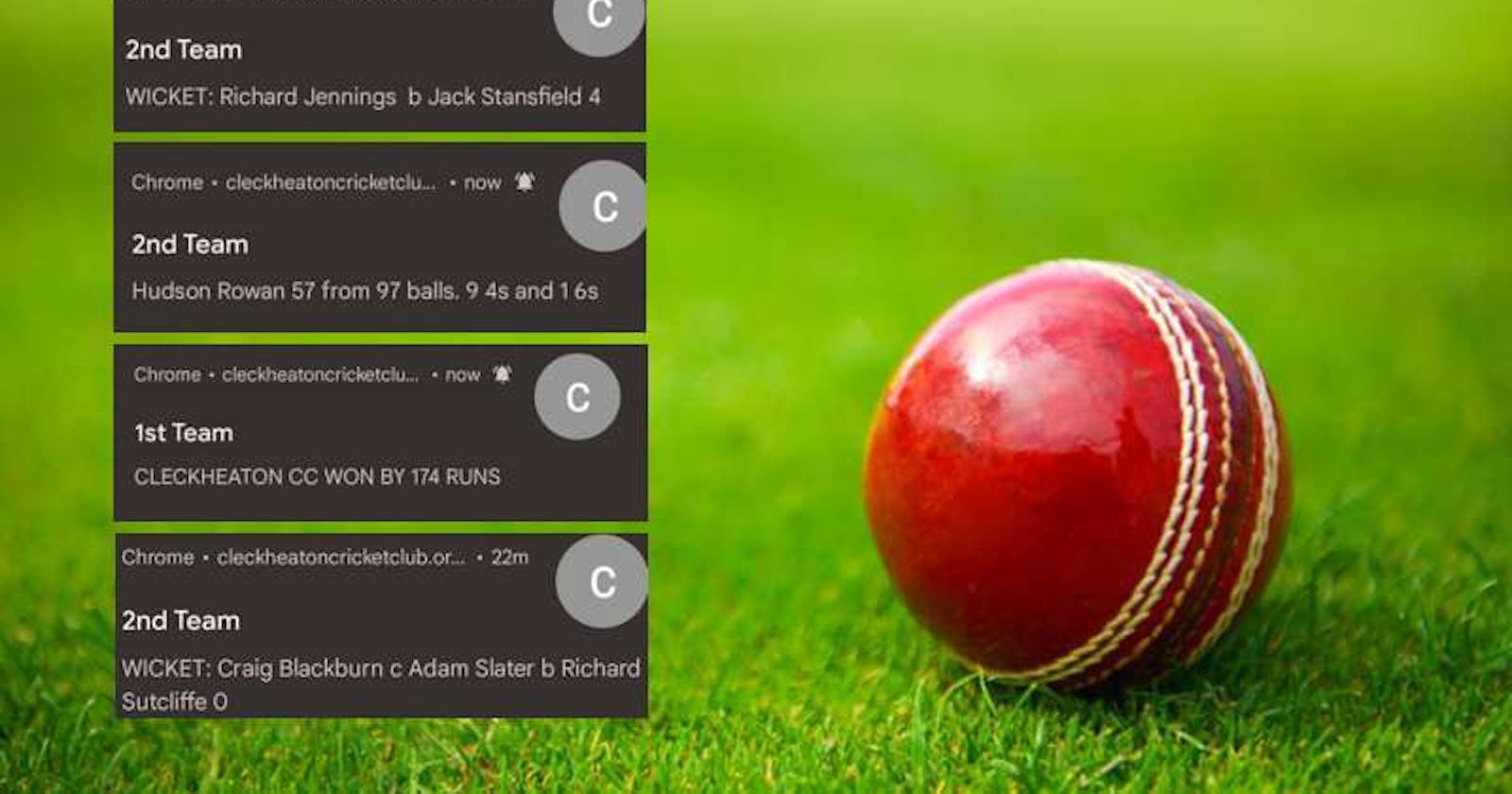
When I was asked to create a new website for the cricket club I played for I figured it would be something I could use to experiment with. Given that my UI skills leave a lot to be desired I didn’t want to do much on the front end so I decided to include up-to-date live scores for both our teams every weekend and allow users to subscribe to receive updates via Web Push to their device during the games.
Goals
Keep supporters up to date as much as possible during the games
Use an event-driven architecture in AWS
Require no manual intervention (I’ve better things to do at the weekend)
Minimal cost as it’s running in my AWS account
Part 1
The first step was to find the raw data and make it available. The live scorecards for each game in the league are available on separate web pages so I needed to find the pages for games involving my club and scrape the latest HTML from them.
Finding the scorecards
Some page interaction was needed with the page before the links were available so Puppeteer seemed like the best choice to open up the page.
It made sense to run this process as a lambda as it should run in under a minute and only once. This sounded fine until trying to deploy to AWS — to cut a long story short Puppeteer needs Chrome binaries and once bundled into a zip file the whole thing is far larger than the 50Mb limit for Lambda. So I ended up creating a lambda layer from chrome-aws-lambda (which is just under 50Mb), removing it from the bundle and referencing it through the layer.
The URLs are stored in Dynamo and the Lambda is invoked by an EventBridge rule every 30 minutes between 12.00 and 14.00 — no games will start before midday so there’s no point running it earlier and it runs more than once in case there’s been a problem with the page. With the URLs being stored in Dynamo it’s easy to check if they already exist at the beginning of the function and return early if they do. Also, these URLs will not be required for any more than around 9 hours so a TTL is added for 24 hours to keep the table clean.
Reading the raw data
Once I have a URL for a game I then need to navigate to the correct tab for the scorecard, extract the relevant HTML, and do something with it.
Again Puppeteer turned out to be my friend except this time it made no sense running as a Lambda. I wanted to get the scores every 5 minutes at the very least, ideally every 20 seconds, to be as up-to-date as possible so it was far more sensible to run the process inside an EC2 instance.
Because the page updates itself, presumably via a WebSocket, I can open up the webpage, navigate to the scorecard tab, every 20 seconds scrape the HTML, and if it’s changed put it on an SQS for processing downstream.
Putting it together
Once the URLs have been added to Dynamo I needed to create an EC2 instance that, when started, would clone the git repo, install dependencies and invoke a process for each of the games that are in progress.
Enabling streams on the Dynamo table and invoking a Lambda function is probably the best choice for this.
Once the lambda receives an insert event from the stream it creates an EC2 instance using the AWS SDK and sets the userdata of the instance to install git, install node, clone the repo, run npm ci and invoke a process for each game that is being played.
const USER_DATA = `#!/bin/bash
yum update -y
yum install -y git
yum install -y pango.x86_64 libXcomposite.x86_64 libXcursor.x86_64 libXdamage.x86_64 libXext.x86_64 libXi.x86_64 libXtst.x86_64 cups-libs.x86_64 libXScrnSaver.x86_64 libXrandr.x86_64 GConf2.x86_64 alsa-lib.x86_64 atk.x86_64 gtk3.x86_64 ipa-gothic-fonts xorg-x11-fonts-100dpi xorg-x11-fonts-75dpi xorg-x11-utils xorg-x11-fonts-cyrillic xorg-x11-fonts-Type1 xorg-x11-fonts-misc
curl -sL https://rpm.nodesource.com/setup_16.x | sudo bash -
yum install -y nodejs
git clone https://github.com/ChrisDobby/cleckheaton-cc.git
cd cleckheaton-cc/live-scores/scorecard-processor
npm ci
`;
const getStartCommand = ({ teamName, scorecardUrl }: ScorecardUrl) => `npm start ${scorecardUrl} ${process.env.PROCESSOR_QUEUE_URL} ${teamName}`;
const createInstance = (scorecardUrls: ScorecardUrl[]) => {
const userData = `${USER_DATA} ${scorecardUrls.map(getStartCommand).join(' & ')}`;
const command = new RunInstancesCommand({
ImageId: 'ami-0d729d2846a86a9e7',
InstanceType: 't2.micro',
MaxCount: 1,
MinCount: 1,
KeyName: 'test-processor',
SecurityGroupIds: [process.env.PROCESSOR_SG_ID as string],
IamInstanceProfile: { Arn: process.env.PROCESSOR_PROFILE_ARN },
UserData: Buffer.from(userData).toString('base64'),
TagSpecifications: [
{
ResourceType: 'instance',
Tags: [
{ Key: 'Owner', Value: 'cleckheaton-cc' },
],
},
],
});
return client.send(command);
};
Originally I had a single EC2 instance per game but, obviously, a single instance will halve the cost!
On the subject of cost, I now have an EC2 instance running and, currently, the only way of terminating it is manually. Instead of relying on myself to both remember to terminate it and to have access to the AWS console to do it every weekend, I added another Lambda function that would search for any instances with the Ownertag set to cleckheaton-cc and terminate them. I can happily invoke this from an EventBridge rule scheduled at 9 pm as it’s very unlikely a game will be going on after that time.
export const handler = async () => {
const command = new DescribeInstancesCommand({
Filters: [{ Name: 'tag:Owner', Values: ['cleckheaton-cc'] }],
});
const instances = await ec2Client.send(command);
const instanceIds = instances.Reservations.flatMap(({ Instances }) =>
Instances?.map(({ InstanceId }) => InstanceId)
).filter(Boolean) as string[];
const terminateCommand = new TerminateInstancesCommand({
InstanceIds: instanceIds,
});
await ec2Client.send(terminateCommand);
};
So at this point, I’m finding the matches that are being played on a particular day, reading the scorecard html for each game every 20 seconds and putting it onto an SQS queue for processing downstream. Also, everything is being cleaned up — the scorecard URLs will be deleted from the table and the EC2 instance will be terminated.
The architecture looks like this:
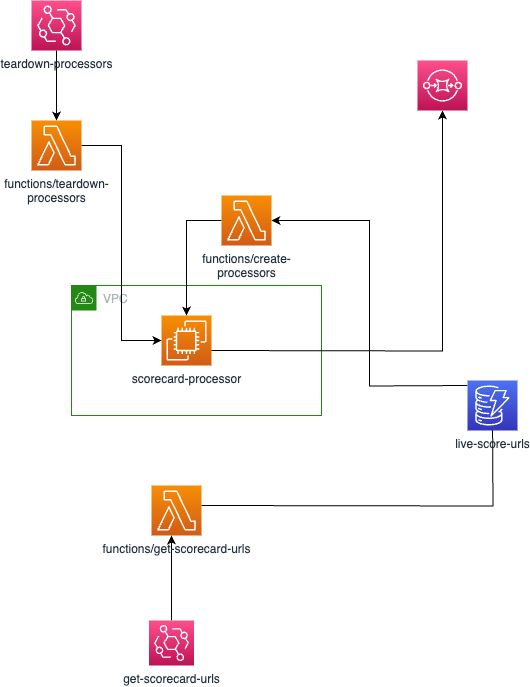
The code for this article can be found on this branch and the full service is here.
Coming next
Part 2 will show how the HTML is processed downstream and the fan-out pattern is used to make several updates.
If you would like to test out the service and get updates through the summer go here and hit Subscribe. Note that on IOS Web Push is only available on v16.4 and above.